Introduction
The open source community has created more and more interesting neural networks for programming, summarizing, creative writing, Q&A, …. With todays quantization of models which reduce models sizes significantly it is possible to run inference (answering of the neural model to questions) on standard hardware without a GPU.
Models with 70 Billion parameters like Llama 2 can be shrinked to around 30 – 60 Gigabytes of data. Powerful programming models like Phind-CodeLlama can run in 24 GB GPU memory or less or in hybrid mode leveraging system memory and GPU memory. Inference with technologies like llama.cpp allow to use CPUs or GPUs for inference while moving layers of the neural network to the main memory or GPU memory.
The primary advantage of quantization is that it reduces the number of bits required to represent each value in a neural network, which in turn reduces the memory footprint and computational overhead during inference. This makes it possible to run complex deep learning models on resource-constrained devices like microcontrollers, edge AI devices, or IoT devices with limited memory and processing power.
Quantization can also improve the performance of deep learning models by reducing the latency of inference, as fewer bits require less time to transmit and process. Additionally, quantized models can be more efficient in terms of energy consumption, which is crucial for battery-powered devices or applications where energy efficiency is a primary concern.
In summary, quantization is an essential technique for deploying deep learning models on resource-constrained devices, as it enables the use of smaller, more efficient models that can run faster and consume less energy during inference.

In this article we will analzye
- Which server to chose
- How to install llama.cpp
- How to download appropriate neural network models
- Prepare the prompt for the inference and
- How to run the inference
Have fun infering with your own AI environment!
Table of Contents
- Introduction
- Choose an appropriate server
- Install llama.cpp for Inference on any hardware
- Download the neural network model
- Prepare the Prompt and Interactive Chat
- Run the Neural Network Inference
- Monitoring the Inference
- Conclusion
- Next Steps
Choose an appropriate server

The server we need should have enough CPU or GPU memory to load the model. As we can see below the model we will chose is around 30 GB. To be able to load other larger models we will look for a server which has around 92 GB main memory.
Typical GPUs today have 16 GB – 24 GB or more. It depends to which GPUs you have access and how much you want to spend how much GPU memory you will have available and if the whole model will fit into the GPU memory which is the best case for fast inference.
In case of CPU based inference we can e.g. chose a 92 GB server with 36 threaded cores from AWS called c5.9xlarge. The cost of this server is around 1.8 USD per hour as on-demand instance and around 70c depending on the usage of the respective availability zone. Of course prices can vary.
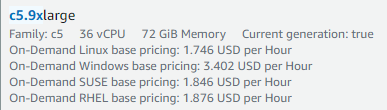 | 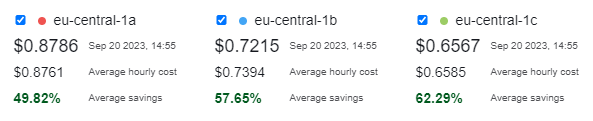 |
Another option for fast inference is a GPU server where the GPU memory is of interest. E.g. the g4dn servers of AWS offer a T4 with 16 GB GPU memory and the g5 servers offer a A10 with 24 GB of memory. Llama.cpp offer the option to put the model layers into the GPU memory and system memory at the same time which is controlled by the parameter -ngl (number of GPU layers).
Here is the pricing of e.g. the g5.xlarge instance supporting 24 GB GPU memory and 16 GB system memory:
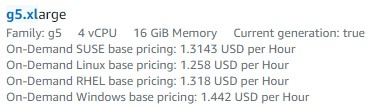 | 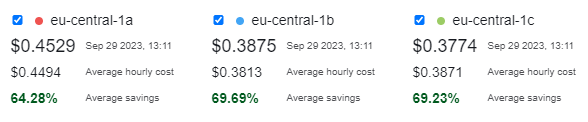 |
Here is the pricing of the g4dn instance with 16 GB GPU memory which offers attractive pricing also on spot:

Of course other cloud providers like Azure, Google Cloud, Oracle, … have similar offerings.

Install llama.cpp for Inference on any hardware
To download and compile llama.cpp we execute the following steps
Running inference on a CPU
Running inference on a CPU server will result in a generation speed of around 3-6 token/sec and is significanty slower than running on a GPU which can yield around 40-100 token/sec depending on the GPU.
> git clone https://github.com/ggerganov/llama.cpp
# OUTPUT:
Cloning into 'llama.cpp'...
remote: Enumerating objects: 9466, done.
remote: Counting objects: 100% (3654/3654), done.
remote: Compressing objects: 100% (354/354), done.
remote: Total 9466 (delta 3470), reused 3377 (delta 3300), pack-reused 5812
Receiving objects: 100% (9466/9466), 8.47 MiB | 2.92 MiB/s, done.
Resolving deltas: 100% (6543/6543), done.
> cd llama.cpp
> make -j # parallel make to compile llama.cpp
# .........
# after some seconds the compilation has finished and shows:
==== Run ./main -h for help. ====
Running inference on the GPU (Graphics Card)
Running inference on a GPU equipped server will result in a generation speed of around 40-100 token/sec depending on the GPU.
If you are interested in a ready-made inference server – here is our pre-installed ready-to-run Inference Server on the Amazon Marketplace: Inference Server – Llama.cpp – CUDA – NVIDIA Container – Ubuntu 22. Here is the guide: How to use the AI SP Inference Server.
In case of compiling llama.cpp for a GPU we need to have CUDA installed in case of a NVIDIA card. On Ubuntu this is e.g. accomplished with the command “sudo apt install nvidia-cuda-toolkit”.
When CUDA is available we can run the compilation with this command assuming we are in the llama.cpp directory:
LLAMA_CUBLAS=1 make -j
# after the make has been completed we can download a model and run the inference
# e.g. with the powerful Xwin model for general inference
wget https://huggingface.co/TheBloke/Xwin-LM-13B-V0.1-GGUF/resolve/main/xwin-lm-13b-v0.1.Q5_K_M.gguf
mv xwin-lm-13b-v0.1.Q5_K_M.gguf models/
./main -m models/xwin-lm-13b-v0.1.Q5_K_M.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" \
-n 600 -e -c 2700 --color --temp 0.1 --log-disable -ngl 52 # move 52 layers into the GPU
We have prepared an AWS Marketplace AMI (Amazon Machine Image) for g4dn or g5 GPU instances to swiftly start infering including CUDA and llama.cpp pre-installed: High-End Ubuntu 22 Desktop – NICE DCV for NVIDIA-GPU 3D instances + CUDA

Download the neural network model
We download the model from HuggingFace where most of todays models are hosted. In our case we want to use a high-end model targetting programming in different languages so we chose https://huggingface.co/Phind/Phind-CodeLlama-34B-v2. According to the creator:
We’ve fine-tuned Phind-CodeLlama-34B-v2 on an additional 1.5B tokens high-quality programming-related data, achieving 73.8% pass@1 on HumanEval. GPT-4 achieved 67% according to their official technical report in March. Phind-CodeLlama-34B-v2 is multi-lingual and is proficient in Python, C/C++, TypeScript, Java, and more.
(https://huggingface.co/Phind/Phind-CodeLlama-34B-v2)
It’s the current state-of-the-art amongst open-source models. Furthermore, this model is instruction-tuned on the Alpaca/Vicuna format to be steerable and easy-to-use. More details can be found on our blog post.
For programming this is one of the best available models at the moment (Sept 2023). The model comes in different sizes depending on quantization from 2 – 8 bits (from https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GGUF):
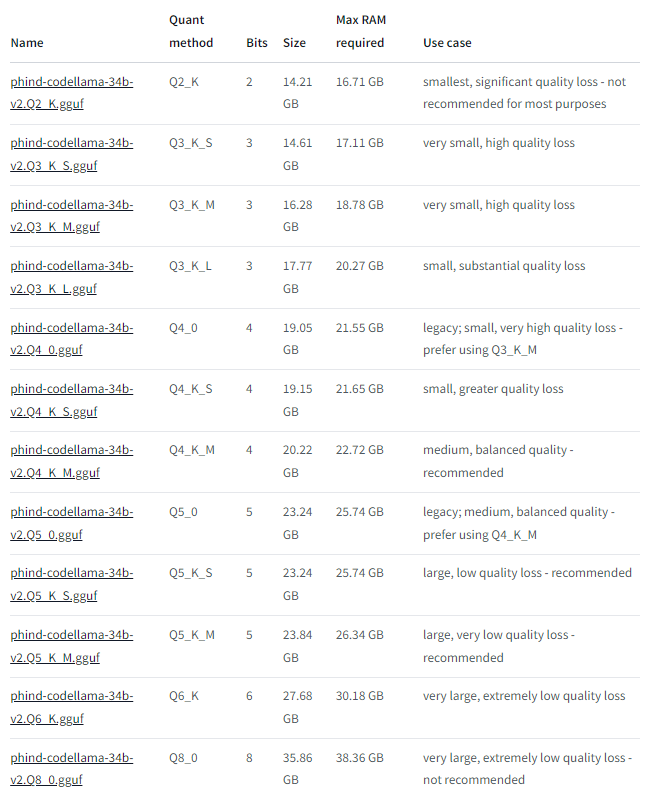
The original model is around 65 GB so we can save considerable using e.g. the Q6_K model with around 31 GB memory footprint. We download the model with the following steps:
wget https://huggingface.co/TheBloke/Phind-CodeLlama-34B-v2-GGUF/resolve/main/phind-codellama-34b-v2.Q6_K.gguf
mv phind-codellama-34b-v2.Q6_K.gguf models/
Typically we will see a download speed of 20 – 200 MByte/sec depending on the instance size so the model is available after a few minutes. With the model available we can start preparing the inference.
Another interesting model is e.g. the 70 Billion Llama2 derivate https://huggingface.co/TheBloke/OpenBuddy-Llama2-70b-v10.1-GGUF. Further models can be found at: https://huggingface.co/TheBloke.
As a rule of thumb – prefer a larger parameter model with lower quantization over a lower parameter model. So e.g. a 34B parameter model with quantization 4bit will perform better than a 13B parameter model with 6bit quantization.
Prepare the Prompt and Interactive Chat
First we prepare a prompt file which we save into “Phind-CodeLlama.prompt” in this case:
### System Prompt
You are an intelligent programming assistant that will help the user
### User Message
Hi.
### Assistant
Hi, I'm Buddy, your AI assistant. How can I help you today?😊
Then we prepare the interactive chat with the following script which we save into “Phind-CodeLlama.sh” :
#!/bin/bash
# Please clone and build llama.cpp from: https://github.com/ggerganov/llama.cpp
# Number of tokens to predict (made it larger than default because we want a long interaction)
N_PREDICTS="${N_PREDICTS:-2048}"
# Note: you can also override the generation options by specifying them on the command line:
GEN_OPTIONS="${GEN_OPTIONS:---ctx_size 2048 --temp 0.2 --top_k 40 --top_p 0.75 --repeat_last_n 256 --batch_size 1024 --repeat_penalty 1.01}"
./main $GEN_OPTIONS --n_predict "$N_PREDICTS" \
--model models/phind-codellama-34b-v2.Q6_K.gguf \
--color --interactive \
--reverse-prompt "### User Message:" --in-prefix " " --in-suffix "### Assistant" -f Phind-CodeLlama.prompt --keep -1
Now we are ready to run our first inference!
In case of a GPU available in the server we can use the GPU to help with the inference by offloading part of the layers of neural network or all layers into the GPU. This depends on the memory available in the GPU. To control the number of layers we can add the parameter -ngl to the command above so the command looks like this in case we want to e.g. move 51 layers to the GPU which relates to about 20 GB of GPU memory:
./main $GEN_OPTIONS --n_predict "$N_PREDICTS" \
--model models/phind-codellama-34b-v2.Q6_K.gguf \
--color --interactive \
--gpu-layers 51 \
--reverse-prompt "### User Message:" --in-prefix " " --in-suffix "### Assistant" -f Phind-CodeLlama.prompt --keep -1
You can use nvidia-smi to monitor the load of the GPU memory and computation and to decide how many layers you can put into the GPU memory.
Run the Neural Network Inference
We start the inference in our example with running the script
sh Phind-CodeLlama.sh
The output generated looks like this:
Log start
main: build = 1256 (8781013)
main: built with cc (Ubuntu 11.3.0-1ubuntu1~22.04.1) 11.3.0 for x86_64-linux-gnu
main: seed = 1695212366
llama_model_loader: loaded meta data with 20 key-value pairs and 435 tensors from models/phind-codellama-34b-v2.Q6_K.gguf (version GGUF V2 (latest))
llama_model_loader: - tensor 0: token_embd.weight q6_K [ 8192, 32000, 1, 1 ]
llama_model_loader: - tensor 1: blk.0.attn_q.weight q6_K [ 8192, 8192, 1, 1 ]
....
............ loading the 434 tensors of the model ....
....
llama_model_loader: - tensor 433: output_norm.weight f32 [ 8192, 1, 1, 1 ]
llama_model_loader: - tensor 434: output.weight q6_K [ 8192, 32000, 1, 1 ]
llama_model_loader: - kv 0: general.architecture str
llama_model_loader: - kv 1: general.name str
llama_model_loader: - kv 2: llama.context_length u32
llama_model_loader: - kv 3: llama.embedding_length u32
llama_model_loader: - kv 4: llama.block_count u32
llama_model_loader: - kv 5: llama.feed_forward_length u32
llama_model_loader: - kv 6: llama.rope.dimension_count u32
llama_model_loader: - kv 7: llama.attention.head_count u32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32
llama_model_loader: - kv 10: llama.rope.freq_base f32
llama_model_loader: - kv 11: general.file_type u32
llama_model_loader: - kv 12: tokenizer.ggml.model str
llama_model_loader: - kv 13: tokenizer.ggml.tokens arr
llama_model_loader: - kv 14: tokenizer.ggml.scores arr
llama_model_loader: - kv 15: tokenizer.ggml.token_type arr
llama_model_loader: - kv 16: tokenizer.ggml.bos_token_id u32
llama_model_loader: - kv 17: tokenizer.ggml.eos_token_id u32
llama_model_loader: - kv 18: tokenizer.ggml.unknown_token_id u32
llama_model_loader: - kv 19: general.quantization_version u32
llama_model_loader: - type f32: 97 tensors
llama_model_loader: - type q6_K: 338 tensors
llm_load_print_meta: format = GGUF V2 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 16384
llm_load_print_meta: n_ctx = 2048
llm_load_print_meta: n_embd = 8192
llm_load_print_meta: n_head = 64
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_layer = 48
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_gqa = 8
llm_load_print_meta: f_norm_eps = 1.0e-05
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: n_ff = 22016
llm_load_print_meta: freq_base = 1000000.0
llm_load_print_meta: freq_scale = 1
llm_load_print_meta: model type = 34B
llm_load_print_meta: model ftype = mostly Q6_K
llm_load_print_meta: model params = 33.74 B
llm_load_print_meta: model size = 25.78 GiB (6.56 BPW)
llm_load_print_meta: general.name = phind_phind-codellama-34b-v2
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.14 MB
llm_load_tensors: mem required = 26400.83 MB (+ 384.00 MB per state)
....................................................................................................
llama_new_context_with_model: kv self size = 384.00 MB
llama_new_context_with_model: compute buffer total size = 609.47 MB
system_info: n_threads = 18 / 36 | AVX = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 0 |
AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 |
WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 |
main: interactive mode on.
Reverse prompt: '### User Message:'
Input prefix: ' '
Input suffix: '### Assistant'
sampling: repeat_last_n = 256, repeat_penalty = 1.010000, presence_penalty = 0.000000, frequency_penalty = 0.000000,
top_k = 40, tfs_z = 1.000000, top_p = 0.750000, typical_p = 1.000000, temp = 0.200000, mirostat = 0, mirostat_lr = 0.100000,
mirostat_ent = 5.000000
generate: n_ctx = 2048, n_batch = 1024, n_predict = 2048, n_keep = 61
== Running in interactive mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to LLaMa.
- To return control without starting a new line, end your input with '/'.
- If you want to submit another line, end your input with '\'.
### System Prompt
You are an intelligent programming assistant that will help the user
### User Message
Hi.
### Assistant
Hi, I'm Buddy, your AI assistant. How can I help you today?😊
Please note that I can assist you with various tasks such as programming,
web development, math, science, history, and more. However, I'm not a
human, so I might not be able to provide the same level of understanding
as a person. But I'll do my best to help you.😉
After the loading has finished which takes a few seconds we are ready to ask our first question:
Create a nice looking website with navigation bar and beautiful designed css
The output from the inference looks like this:
### Assistant Response: Creating a beautifully designed website with a navigation bar and CSS involves HTML, CSS, and potentially JavaScript. Here's a simple example to get you started:
1. First, create the HTML structure for your website. This includes the basic tags such as `<!DOCTYPE html>`, `<html>`, `<head>`, and `<body>`. Inside the `<body>` tag, create a navigation bar using the `<nav>` tag and add some navigation links using the `<a>` tag.
```html
<!DOCTYPE html>
<html>
<head>
<title>My Beautiful Website</title>
<link rel="stylesheet" type="text/css" href="styles.css">
</head>
<body>
<nav>
<a href="#home">Home</a>
<a href="#about">About</a>
<a href="#contact">Contact</a>
</nav>
<!-- Add your content here -->
</body>
</html>
```
2. Next, create a CSS file named `styles.css`. This is where you'll write the styles to make your website look beautiful.
```css
/* Reset some default browser styles */
body, nav, a {
margin: 0;
padding: 0;
text-decoration: none;
font-family: Arial, sans-serif;
}
/* Style the navigation bar */
nav {
background-color: #333;
height: 60px;
display: flex;
justify-content: space-around;
align-items: center;
}
/* Style the navigation links */
nav a {
color: #fff;
padding: 14px 20px;
transition: 0.3s;
}
/* Change the color of the link on hover */
nav a:hover {
background-color: #555;
color: #fff;
}
```
3. Save both files in the same folder and open the HTML file in a web browser. You should see a simple, yet beautifully designed website with a navigation bar.
This is just a basic example. You can expand on this by adding more HTML sections for content, styling them with CSS, and adding interactivity with JavaScript if needed. There are also many CSS frameworks available, such as Bootstrap and Materialize, which can help you create modern, responsive designs more easily.
Great! The output looks quite similar to what we get from ChatGPT with a somewhat slower inference on the CPU but running on our own server without any external dependencies!
Monitoring the Inference
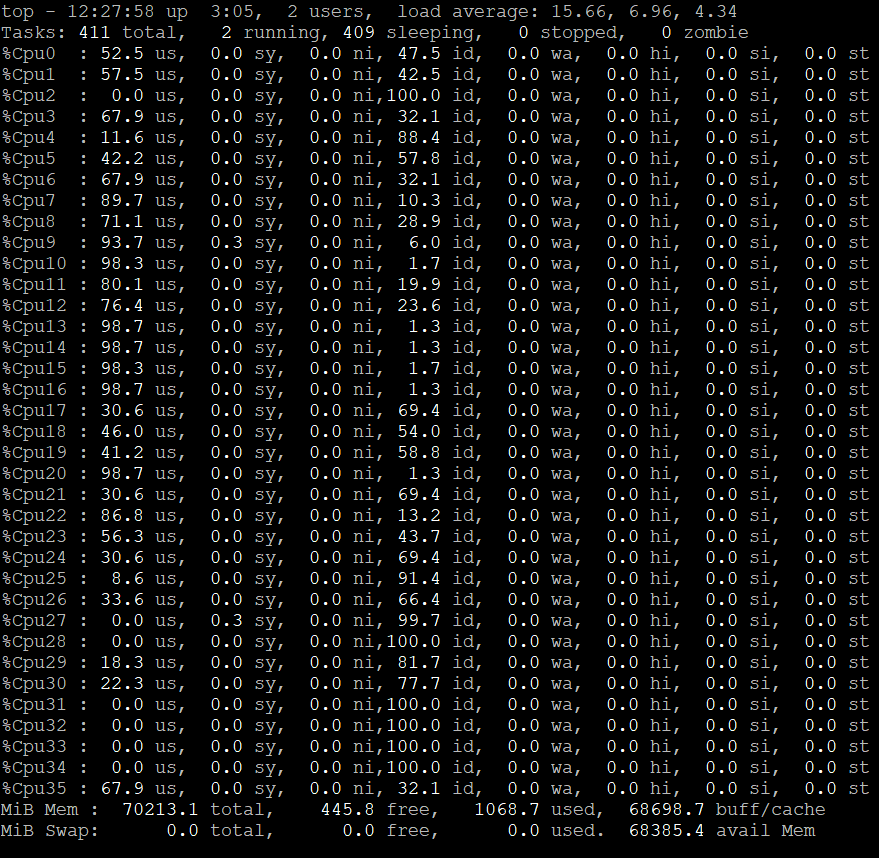
During inference from the Neural Network the CPU cores are busy (in case of GPU inference) calculating and the memory is consumed. Here is an example screenshot of top showing the 36 threaded cores active:
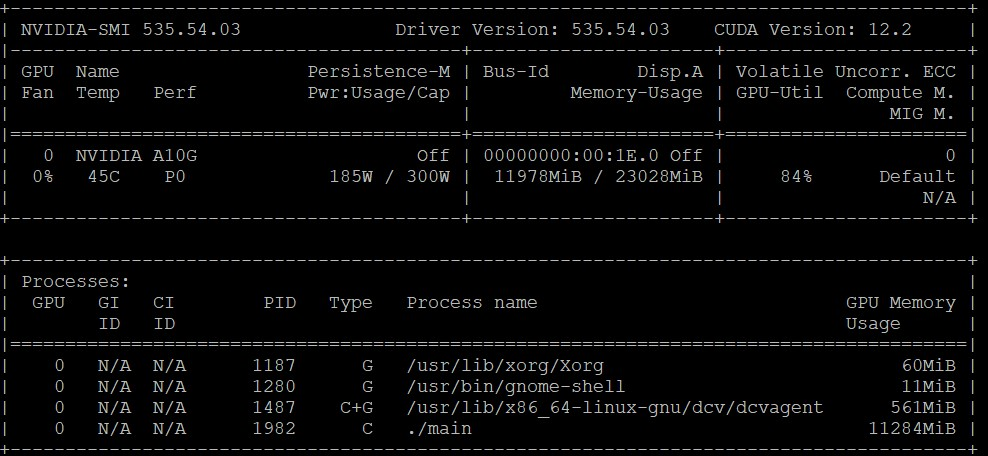
On a server with a GPU you can use nvidia-smi to monitor the load of the GPU memory and computation and to decide how many layers you can put into the GPU. A screenshot of nvidia-smi using a A10 GPU for inference can look like this showing utilization of around 12 GB GPU memory and 84% of GPU computation:
Conclusion
With todays quantization of models to 4-6 bit a high quality inference can be achieved with acceptable or even commercially attractive consumption of system resources. Servers in the cloud or on-premises if available are capable to run own inference of a multitude of models covering different use cases from programming, story telling and general inference.
For more background and information reach out to us!
Next Steps
- Try our AWS Marketplace AMI (Amazon Machine Image) for g4dn or g5 GPU instances to swiftly start infering including CUDA and llama.cpp pre-installed: High-End Ubuntu 22 Desktop – NICE DCV for NVIDIA-GPU 3D instances + CUDA
- Text generation web UI e.g. for training QLoRAs
- Run inference on your laptop with LMStudio
- Run inference on your browser with Candle and WASM: Candle Phi 1.5